
This is the first of a series of posts that will explain the inner workings of ChatGPT, step by step. Today’s topic is ChatGPT’s vocabulary. When ChatGPT generates text, it does so by selecting words from an internal vocabulary of 100,261 different words (or piece of words). ChatGPT’s vocabulary has some curious words in it. For example, the word ” davidjl” is part of the vocabulary, which is the username of a prolific Reddit poster. In this post, we’ll discuss how these words were chosen. We’ll also see how ChatGPT copes with non-English words.
But before we get started with the vocabulary, let me quickly share a birds-eye view of what ChatGPT does and how it was built, which will help us put things in perspective. Let’s go!
ChatGPT in a nutshell
Supposed I asked you to predict the word that comes after the incomplete sentence “The Eiffel.” You’re very likely to suggest that “Tower” is the most logical continuation. A large language model, or LLM, is a computer program especially designed to perform that task: given any input prompt, it tries to guess the word that would most naturallly come afterward (we’ll make this idea more precise later on). So, we can think of an LLM as a sophisticated “autocomplete” program. ChatGPT, created by OpenAI, is a large language model.
The autocomplete task may seem simple at first, but it’s really powerful. Consider the following prompt given to a language model:
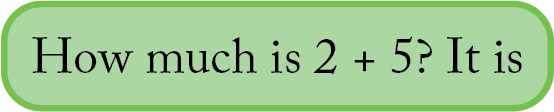
In order to determine that “7” is the most likely continuation of this prompt, the language model must know how to add numbers or perhaps find a suitable shortcut to achieve the same result.
Now, consider the following prompt:

In order to guess the next word accurately, the language model must be capable of translating French to English.
As we can see from these examples, in order to perform the autocomplete task effectively, the language model must know how to perform many differenet complicated tasks, including arithmetic and translation. Some people have even argued that the autocomplete task encompasses all other tasks because we can ask a language model to perform any task by describing it in the prompt.
The creators of ChatGPT had a lot of faith in the potential of autocomplete. In a research paper they said, “Our speculation is that a language model with sufficient capacity will begin to learn to infer and perform [more challenging] tasks.”[1] Indeed, as researchers made their language models bigger, that prediction turn out to be true; the gigantic GPT-3 model, for example, was able to translates text and answer all kinds of questions quite accurately.
While guessing the next word is powerful, in general we want AI to output much longer text, perhaps entire paragraphs. This is achieved easily with language models: we just have the language model eat its own output repeatedly to generate more text, one word a time. Suppose we give ChatGPT the prompt “The Eiffel.” The chatbot guesses the most likely continuation of the sentence—“Tower”—and attaches it to the initial prompt, which leads to “The Eiffel Tower.” It then guesses the following word, say, “it,” and attaches it to the prompt. The process is repeated again and again:
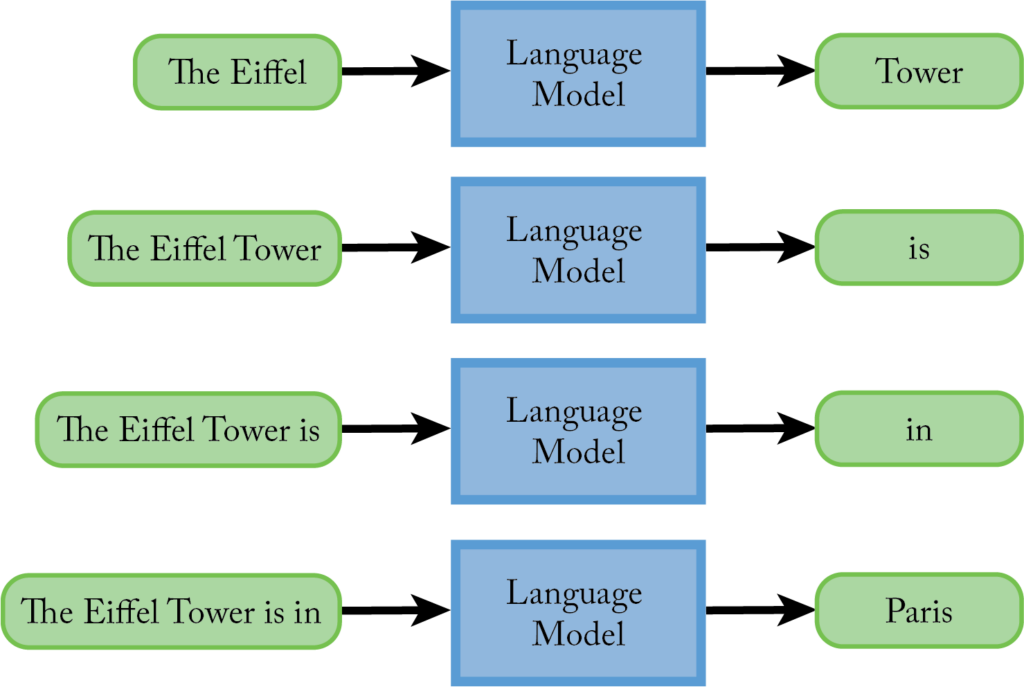
We end up with “The Eiffel Tower is in Paris,” and we could generate much more text if we wanted to.
Language models aren’t built by hand, writing thousands of rules manually; that would be too complicated and impractical. Instead, they are built by using a technique called machine learning. In this technique, a computer automatically learns how to perform a task by example.
In the case of ChatGPT, the researchers took a huge snapshot of text from the internet (this was in 2021, so that’s as far as ChatGPT’s knowledge goes). This is known as the training data. Afterward, they created billions of examples of how to perform the autocomplete task from this data. Suppose the sentence “The Eiffel Tower is in Paris” appeared in the data. The researchers created numerous examples of the autocomplete task as follows:
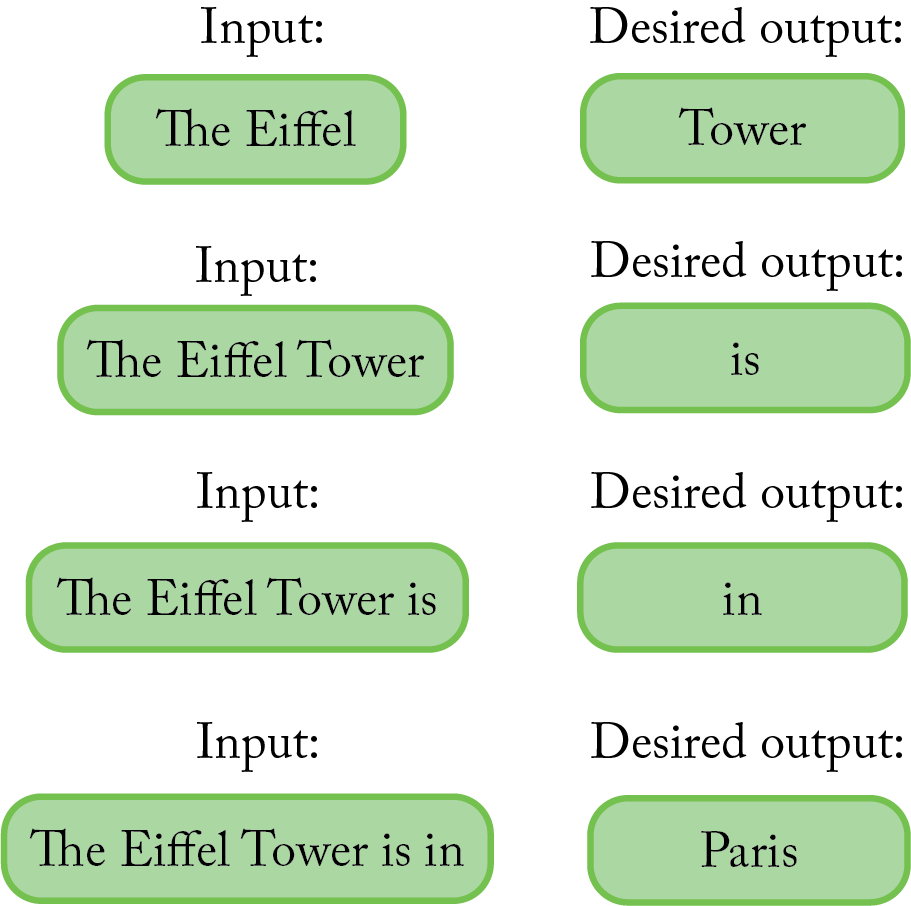
After creating this database of examples, the researchers ran a lengthy computer program to make ChatGPT learn, which is often described as training the model. During this stage, the language model was refined over and over again hoping to make it better at predicting the next word in the given examples. The process of learning was akin to a visit to the eye doctor for a glasses prescription—the doctor starts with a lens that might be totally far off, but progressively improves the prescription based on your feedback until finding the right one.
The resulting model trained using this approach achieved impressive performance. However, it was still quite weak at certain tasks. Moreover, the model outputted inappropriate stuff sometimes, and the people from OpenAI weren’t happy about that. They said: “predicting the next word on a webpage from the internet is different from the objective of following the user’s instructions helpfully and safely.” [2]
So, the next step was a painstaking effort to “tame” ChatGPT. This involved writing thousands of additional learning examples by hand, instead of just collecting them from the internet. These carefully written examples tried to show ChatGPT how to answer delicate questions and how to converse effectively, among other things. The researchers then ran an additional learning phase to refine the existing model using these new, manually created examples. This additional learning phase, called fine-tuning, was much shorter than the previous one, as it was meant to just adjust the existing model instead of building it from scratch. The result was a language model particularly tailored to dialog, and they called it ChatGPT.
Vocabulary
When we humans communicate, we select our words from a mental vocabulary. This vocabulary includes common words, such as “dog” and “friendly.” It also includes common pieces of words, such as “ish,” “ly” or “th,” which help us invent new words that don’t appear in the dictionary, like “hungryish.” Our mental vocabulary also includes individual letters, which allows us to spell out words and read acronyms.
ChatGPT is quite similar—it contains a fixed vocabulary with a vast list of common words, like “dog” and “friendly.” The vocabulary also contains common pieces of words, like “ish,” and individual letters. ChatGPT’s vocabulary contains a total of 100,261 different elements. Each of these elements is known as a token.
In the following, we’ll discuss why ChatGPT needs a vocabulary, how its vocabulary was created, and how it is used.
One token at a time
Every time ChatGPT autocompletes a bit of text, it does so by picking a single token from its vocabulary. For example, I asked ChatGPT to complete the sentence “The dog’s bark was barely”, and it outputted “ audible”. It did so by selecting token number 80,415 out of its 100,261 available tokens, which corresponds to “ audible” (the word “audible” with a leading space).
Let’s see how this lets ChatGPT output words that aren’t in the dictionary. I asked ChatGPT, “What do I mean if I say I’m hungryish, briefly?” Have a look at its answer, where different colors are used to indicate the different tokens that ChatGPT outputted one by one:

Note that the word “hungryish,” which isn’t in the English dictionary, was produced by outputting first the token “ hungry” and then the token “ish.” The word “milder” was also produced in two steps, “ mild” and “er,” and contractions like “I’m,” “you’re” and “It’s” were also outputted in two pieces.
So, while we often hear that language models guess or autocomplete “the next word,” they technically guess the next token, which could be a piece of a word. When ChatGPT outputs a long sentence, for example, it does so by outputting a sequence of tokens, one at a time (at the end of this post, we’ll see how ChatGPT knows when to stop outputting tokens).
ChatGPT’s basic tokens
Let’s have a look now at how ChatGPT’s vocabulary was created by OpenAI’s researchers. The first step was to choose the basic, indivisible tokens of the vocabulary, like “a” and “b,” which can be part of longer words. The reseachers wanted ChatGPT to cope with symbols like “©” and non-Latin alphabets like Chinese. However, creating one basic token for every possible character wasn’t an option, as there are tens of thousands of different characters in all the world’s languages combined.
To solve this conundrum, they resorted to a popular computer standard, known as UTF-8, which is capable of representing all sorts of characters by using only 245 different symbols. It works as follows: The most common punctuation marks, numbers and Latin letters have a dedicated symbol in UTF-8—there are 95 of those. The remaining 150 symbols are used to represent “pieces” of other, less common characters. For example, the Chinese character 你 is represented by a sequence of three special symbols.
ChatGPT’s basic vocabulary includes one token for each of the 245 different UTF-8 symbols. This way, it can output any individual English letter, such as “a” and “b,” but it can also output Chinese characters and symbols like “©,” one piece at a time.
In case you’re curious, these are ChatGPT’s basic tokens:

Note that ChatGPT’s vocabulary includes 11 tokens to represent UTF-8 special symbols that don’t actually exist, which was probably an accident. So, ChatGPT’s basic vocabulary consists of a total of 256 tokens, 11 more than the 245 symbols of UTF-8. These extra 11 tokens are duds that are never found in real text and are hopefully never outputted by ChatGPT.
ChatGPT’s derived tokens
The next step was to enhance ChatGPT’s vocabulary by adding thousands of tokens that represent common words or pieces of words. For that, the creators of ChatGPT ran a piece of software to analyze a millions of webpages and find the most common groups of characters in them.
We don’t know for sure what this data looked like beacuse OpenAI hasn’t disclosed the details. However, we do know which data they used to create the (smaller) vocabulary of ChatGPT’s precursor, GPT-3. That database was created by automatically following links posted on Reddit and downloading the content of the linked webpages. In total, 45 million links were followed, making sure they’d been flagged as useful by Reddit users (a minimum “karma” of three was required). After deduplicating and cleaning the results, this resulted in a database of 8 million documents. It is likely that OpenAI used this same data, or something similar, to create ChatGPT’s vocabulary.
Once all the data was collected, the next step was to subdivide it into individual tokens by using ChatGPT’s basic vocabulary. Here’s an example of what this would look like for a short sentence:

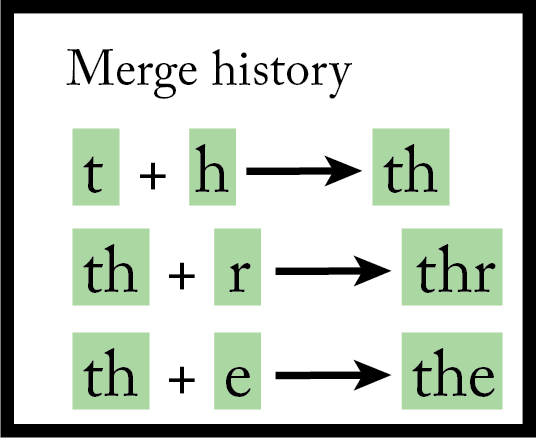
Afterward, an automated program searched for the most common pair of tokens in the entire database. Suppose the most common pair of tokens was “t” followed by “h”. The next step was to create a new token “th” and replace all occurences of “t” “h” in the database with “th”:
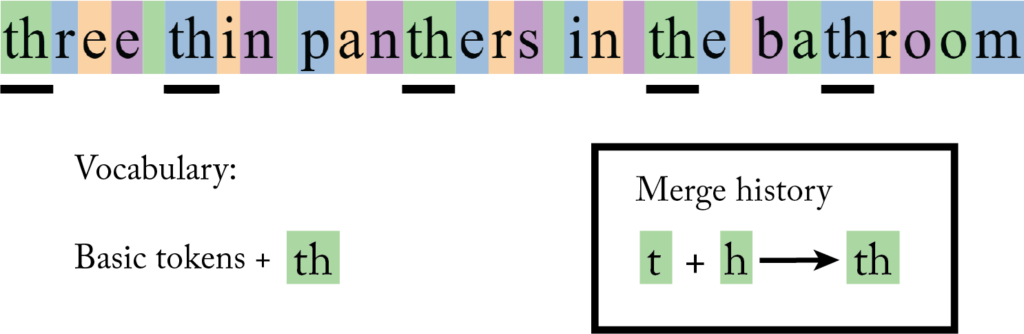
As we can see in the illustration, after merging “t” with “h” the vocabulary was extended to include the new token “th” and that the merge was recorded in a document (we’ll see why in a minute).
The process was repeated again and again, searching for the most common pair of adjacent tokens in the database (both original or the result of previous merges) and combining them. Here’s an illustration of the next step, assuming that “th” was merged with “r”:

And let’s see yet another sample step, after “th” was merged with “e”:

The process went on and on, growing the vocabulary one token at a time. A few undesirable merges were forbidden during this process to help keep tokens meaningful:
- It was not allowed to merge the sequences ’s, ‘t, ‘re, ‘ve, ‘m, ‘ll and ‘d with anything else. So, ChatGPT’s vocabulary does not contain contractions like “we’ll” or “they’d” (note, however, how English-focused this rule is);
- Digits were never merged with anything other than digits, except perhaps a single preceding space, and a maximum of three digits could be merged together. This allowed to create tokens like “123” and ” 123″ but never “123*” or “1234”;
- Letters could only be merged with other letters, except perhaps a single preceding space or symbol. This allowed tokens like “part”, ” part” and “(part” but never “part)” or “part!”.
The researchers performed 100,000 merges, which grew the vocabulary to a size of 100,256 tokens (the 256 basic tokens plus the 100,000 ones that resulted from the merges).
Here is the a list with some of the first few tokens added to the vocabulary:
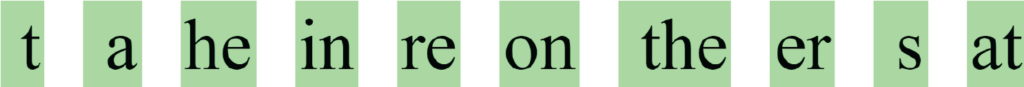
We can see that one of the first fews tokens was a space followed by a “t”; that’s because it’s one of the most common combination of characters in English (think of all the instances of “the” and “to” that we find in text, right after a space). We can also see other predictably common combinations of letters like “he”, “ the” and “at”.
Here’s the real list of the last few tokens added to the vocabulary:

Many tokens in the vocabulary represent words typically used in programming languages, such as “DataFrame” and “(IServiceCollection”. This makes it easy for ChatGPT to output programming code.
The vocabulary contains many curious tokens like ” davidjl”. People suspect it comes from the name of a prolific Reddit posted called “davidjl123” (you can follow the discussion here and here).
Note that most of ChatGPT’s tokens start with a space. This is quite handy because ChatGPT doesn’t have to make the effort of outputting spaces one by one between words; the space comes along with the token.
I created this tool that lets you see all of ChatGPT’s tokens and search for tokens of interest:
You could try to see if your name (or perhaps your Reddit username) appears in the list. My name has its own dedicated token but only with a leading space. You can find more info about this list here.
From input prompt to tokens
In addition to outputting tokens, ChatGPT also reads the input as a sequence of tokens. This means that an input prompt must be subdivided into valid tokens from the vocabulary; it must be “tokenized.” If possible, we want to have as large tokens as we can, in order to avoid overdividing words into meaningless units. Let’s briefly discuss how the process goes.
Suppose we input the prompt “three thin panthers in the bathroom.” The tokenizer first subdivides the prompt to the finest possible level using ChatGPT’s basic vocabulary:

Now, if you remember, we had created a record of merges when the vocabulary was created:
The merges in this record are then applied one by one, in order, to the input prompt. In this example, any occurences of “t” followed by “h” are replaced with the combined “th” token, then pairs of “th” and “r” are replaced with “thr”, and so on. The process ends after all merges in the record have been considered (all 100,000 of them). We end up with a nicely tokenized prompt:

OpenAI has a friendly webpage that lets you input a prompt and see how it’s split up into tokens by ChatGPT. You can try it out here: https://platform.openai.com/tokenizer.
What about languages other than English?
ChatGPT’s vocabulary is optimized for the English language because most of the text in the database used to create it was in English. Have a look at how the preamble of the U.S. constitution is tokenized:

And now have a look at its French translation:

The French counterpart takes more than twice the number of tokens and the subdivision of words doesn’t make much sense; have a look, for example, at how “États-Unis d’Amérique” (United States of America) was chopped up into many meaningless pieces.
This issue gets even more serious with non-Latin alphabets. An extreme example that has been discussed around the internet is the word for “woman” in Telegu, one of the Indian languages:
స్త్రీ
This word is made up of a combination of six characters arranged horizontally and vertically, and each of them is represented by three special UTF-8 symbols. So, the word is made up of a sequence of 18 UTF-8 symbols in total. As none of these special symbols were merged into larger tokens when ChatGPT’s vocabulary was created, the word must be represented by its 18 basic tokens. So, it takes 18 tokens to represent that single word as opposed to one token in English.
The poor tokenization of non-English text is challenging for ChatGPT because it needs to work extra hard to make sense of text. It’s also more expensive for professional ChatGPT users (who interact with it programmatically) because it is billed by the number of tokens inputted and outputted. If we use ChatGPT in, say, French, it is more expensive than in English, as around twice as many tokens are used for equivalent text. If we use it in, say, Chinese or Telegu, where individual characters are sometimes split into many tokens, it becomes even more expensive.
This sounds unfair to languages other than English. However, a solution to this problem isn’t straightforward. If we wanted to better tokenize non-English words, the vocabulary would have to include words or common pieces of words in French, Chinese, Telegu, and so on. But this would make the vocabulary much larger, well beyond the current 100,000 mark, which could turn ChatGPT ineffective and slow.
Why does ChatGPT need tokens anyway?
ChatGPT’s vocabulary could just contain individual letters, which would allow it to output any word one letter at a time. For example, the word “Paris” could be outputted as “P” “a” “r” “i” “s”, so why have a “Paris” token at all?
Researchers have tried to build a language model that guesses the next letter given a prompt, instead of the next token, and it didn’t work well. The reason is that, internally, language models try to represent the meaning of each input token. And it’s much easier to represent the meaning of a token like “Paris”, for example, by mapping it to the meaning “capital of France,” than to represent the meaning of a token like “P”. The latter would require disambiguating the token based on the context to figure out what “P” refers to.
We could take this idea to the extreme and create a huge vocabulary that includes all sorts of words and their derivatives, like “Parisian,” “Parisians,” “Paris-type,” and “Emily in Paris.” But this would go too far—the vocabulary would become huge and there would be many different tokens to represent closely related words. So, having a token for “Paris” and another one for “ian”, which allows ChatGPT to output “Parisian” in two steps, is a good middle ground.
Special tokens (and how ChatGPT knows when to stop)
ChatGPT outputs one token at a time, over and over, but how does it decide to stop?
The creators of ChatGPT added a special token to its vocabulary, called “<end of text>” (the brackets are used to indicate that it’s a special token). The token is special because, even though it’s part of the vocabulary, it’s not really used to generate readable text. Instead, ChatGPT outputs this special token when it predicts that the text should end.
Here’s an example of a complete ChatGPT output:
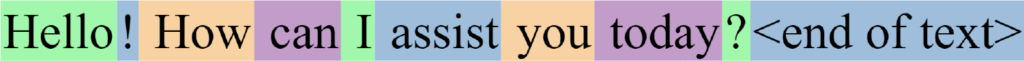
Whenever the chatbot outputs the special “<end of text>” token, it stops generating more text, and the special token isn’t shown to the user.
The special “<end of text>” token was inserted into the training data at the end of individual documents (for example, “Thank you for your help. Kind regards, John.<|end of text|>”). This way, guessing the end of text was treated like an ordinary autocomplete task; just like ChatGPT learned that “Tower” usually comes after “The Eiffel,” it also learned when “<end of text>”, and thus the end of a document is likely to come next.
Another useful special token added to the vocabulary was <end of prompt>. If you remember, during the fine-tuning phase, the training data was extended with lots of manually written sentences to show to ChatGPT how to answer questions appropriately. The “<end of prompt>” token was inserted in this additional training data to indicate the end of the prompt and the beginning of the expected answer:
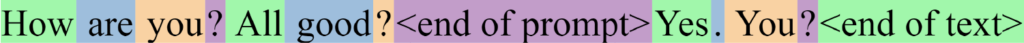
This helped ChatGPT become better at conversation because it made it easier to distinguish prompts from expected answers in the training data.
Finally, three more special tokens were added, called “<prefix>”, “<middle>” and “<suffix>”. Suppose you want ChatGPT to fill in a blank in the middle of a prompt, say, fill in the X in “I visited X, the capital of France.” Instead of explaining to ChatGPT that it should fill in the X, it is possible to explicitly instruct it to do so by using the three special tokens as follows:

When ChatGPT predicts the next token, it will try to guess the word that best fills in the missing text where the token “<suffix>” was inserted; in this case, we hope it will output ” Paris”. ChatGPT was explicitly trained to perform this task by randomly scrambling some of its training data as follows:

This functionality isn’t well known to the general public, but it’s available to professional users.
These five special tokens increased ChatGPT’s vocabulary from 100,256 to 100,261 tokens. There are signs that there might be a few more special tokens with other roles, but nothing has been said about them officially.
Next steps
In the next blog post, I’ll explain how ChatGPT represents the meaning of tokens, which is essential to perform the autcomplete task satisfactorily. We’ll also see how machine learning helps at that task. See you soon!
[1] https://openai.com/research/better-language-models On this link you can download the paper where OpenAI researchers express their enthusiasm about language models’ potential.
[2] https://openai.com/research/better-language-models Here’s the paper where OpenAI researchers explained how they tamed their models.

