ChatGPT contains an internal vocabulary of 100,261 different tokens, which correspond to common words, pieces of words and characters. You can find a full explanation of how the vocabulary was generated and how it’s used here.
This is the full (scrollable) list of tokens:
Notes:
- Some tokens contain special bytes that don’t correspond one by one to human-readable characters (they are used in tandem to represent non-Latin characters in the UTF-8 encoding). These are indicated by their hexadecimal code (underlined).
- If a token with special bytes can be decoded as a valid piece of text, the decoded text is shown inside a blue box:
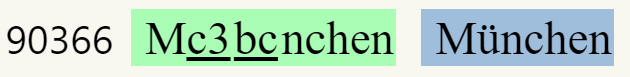
- The last few tokens are special tokens (described here). Note that their IDs are not contiguous. This suggests there might be more special tokens that haven’t been officially explained by OpenAI:
